Gas, Whey & Lobsters and Indian-Homework
Table of contents
Whey, gas and lobsters
Wrongfully castigating an invaluable resource as wasteful dross has been one of humanity’s most original, artful and cardinal sins.
-
Whey - Gutter-to-Gold: Till the development of membrane filtration technologies in the 1960s, protein-rich sweet whey was literally disposed down the drains by the dairy industry. Today, it is widely considered to be the go-to protein choice for most fitness fanatics with a burgeoning multi-billion market. Also, it is painful to imagine the civilizational cost we paid for not building out distribution pipelines for this nutritious by-product to be shared amongst the masses & ensure they got sustained on high-protein diets!
](/alignchronicles/assets/images/posts/whey_image.png)
Source: https://www.sciencedirect.com/science/article/pii/S0924224421005124
- Natural gas - Invisible fuel: Natural gas was historically considered a worthless byproduct of oil drilling and was often burned at the wellhead. Vast amounts of engineering clock cycles were abused to invent techniques such as Optimal-venting and Production-flaring with the sole goal to efficiently dispose this invaluable resource right up until the early part of the 20th century. Today, it is not only hailed as the cleanest fossil fuel but also considered to be ‘an integral part of green-energy strategies around the world as the bridge-fuel of choice!
- Lobsters- Cockroach to Caviar: Lobsters were once called the “cockroaches of the sea,” a stigmatized scavenger so abundant in colonial New England that they would wash ashore in knee-deep piles after storms. Far from the luxury status they enjoy today, these crustaceans were viewed as the “protein of the bad man,” a cheap and “cruel” filler fed to prisoners and indentured servants. Today, it is a high end gourmet protein served in high-end restaurants and currently sustains a 7 Billion market growing at scorching pace.
India’s silent crime: Throwing away the homework treasure-trove
Alongside the Whey, Gas and Lobster triad, I believe lies India’s homework treasure-trove. India criminally throws away its academic data goldmine that is the reams and reams of graded homework her students produce every day!
The numbers: Assuming an average student takes 6 courses and generates roughly 100 KB worth of data via homework, assignments and tests, we have a mindboggling 998.4 GB of data being generated every academic calendar year spanning 32 weeks by a single academic group like the Jain group (that boasts of a student body of 51600 students). This data-trove, as we type this, is currently getting discarded into abyss never to be utilized in any way and the scale of this wastage is mindboggling. To put things into perspective, this data mined thus from a single academic group in a single year spans more than [The Pile](https://arxiv.org/abs/2101.00027), that is one of the largest openly available dataset (that is only 825 GB). Add in the fact that much of this has been graded by a human evaluator (examiner evaluating grades and providing feedback notes) facilitates rich algorithmic advances that the field is yet to see!

The data moat is a data iceberg!
Now comes the obvious question: Whey had its “Protein moment”. Lobsters had its “Gourmet moment”. Natural Gas had its “Bridge-fuel” moment. What would be the X in Indian homework’s X moment? I posit it would be that graded homework will have its “RL (Reinforcement Learning) moment”. In the following sections I will motivate how India’s gargantuan base of graded homework can be a game-charger for progressing state-of-the-art AI towards it prophesized “AGI” moment and how it could be orchestrated ethically and profitably.
A peek into how SOTA AI/LLMs are trained
](/alignchronicles/assets/images/posts/whey_image%201.png)
The pipeline was sourced from: https://allenai.org/blog/olmo3
As seen in the figure above, the state-of-the-art AI/Large Language Model training pipeline is largely dichotomized into two phases: The pre-training phase (or the boring dead phase) that results in a “Base Model”. The post-training phase that results in “Thinking Models”.
The state-of-the-art pre-training data is mostly derived from Common-Crawl (4.5T tokens our 6T tokens for the Dolma3) and augmented with academic publications, code etc. This part of the pipeline is widely believed to be the boring part or even the dead part with most the WWW being already scraped dry. The post-training phase is where the real action is and the real fun begins. The base model that emerges freshly baked from the pre-training phase is just an unaligned token-predictor that is unworthy of an real economic utility and most certainly un-deployable as a a chatbot. But when it is subjected to a guided Reinforcement Learning from Human Feedback (RLHF) /. Supervised Fine-Tuning phase (See figure below taken from Andrej Karpathy’s canonical talk), it turns into chat-bot styled Thinking model that is also putatively aligned with complex “human values”.
 - State of GPT talk by Andrej Karpathy](/alignchronicles/assets/images/posts/whey_image%202.png)
Source: https://www.youtube.com/watch?v=bZQun8Y4L2A - State of GPT talk by Andrej Karpathy
This phase of human preference alignment is currently stricken with serious shortcomings, is widely known to be a specialized dark-art and this is also where the data-labelers’ gold-rush has been in. From the algorithmic efficiency perspective, experts such as Yann LeCun have repeatedly expressed deep suspicion on its inefficiency while once even branding it “hopeless” (See Tweet screenshot below).
](/alignchronicles/assets/images/posts/whey_image%203.png)
https://x.com/search?q=from%3Aylecun RLHF is hopeless&src=typed_query
The main nuance is that RL generally is a beast that appears to be quack-science in low-data regimes that suddenly awakens into a formidable beast in the large-data regime whilst being aggressively data inefficient. In fact, there’s an entire cottage industry of literature on the so-termed breathtakingly inefficient scaling nature of RL-scaling.
It is precisely this inefficiency that has birthed overnight unicorns such as Mercor, Surge and Scale AI ( Semianalysis has an absolutely brilliantly blogpost covering this). And it is precisely here that India’s civilizational play lies. If we can build a bridge between India’s civilizational moat and the RL training pipelines, this will accelerate AI timelines at a rate beyond an AI-maximalist’s imaginations.
The roadblocks and the concerns
The current orchestration mechanism for collecting the human feedback is fraught with other serious ethical shortcomings such as:
- Labor exploitation: An investigation by Time magazine revealed that [OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic](https://time.com/6247678/openai-chatgpt-kenya-workers/). This fits squarely in the larger pattern of abusive labor practices that was hitherto used for content moderation jobs and are now being replicated under the banner of RLHF. Besides the monetary perspective, we also have to grapple with the psychological and emotional impact on the workers and labelers being exposed to toxic textual and visual content that they are expected to provide feedback about.
- Scalability and quality: It is rather self-evident that scaling computation by recruiting larger swathes of GPU-laden server farms is much easier compared to scaling up human labor and latency. Google cloud rents out the state-of-the-art A100 GPUs for as little as $0.87 per hour! Human labor on the other hand is expensive, requires substantial managerial overhead, slow (oft capped at 40hrs/week), error-ridden and is fraught with threat vectors such as malicious/adversarial labelers.
- Who’s ethics are getting baked in during RLHF? When Time’s expose of using cheap Kenyan labor for RLHF was unveiled, the question of the responses having imbibed localized Kenyan ethics was raised in several social media platforms. While this insinuation is reductionist, the more nuanced notion that constructs such as toxicity, offensiveness and malignity are contextualized differently in different social-temporal contexts is extremely important to consider. It is but foolhardy to believe that a model trained on a blackbox dataset scraped from the internet in a San Francisco lab and finetuned with the responses of exploited Kenyan human labor would be ethically robust in a complex setting such as India’s.
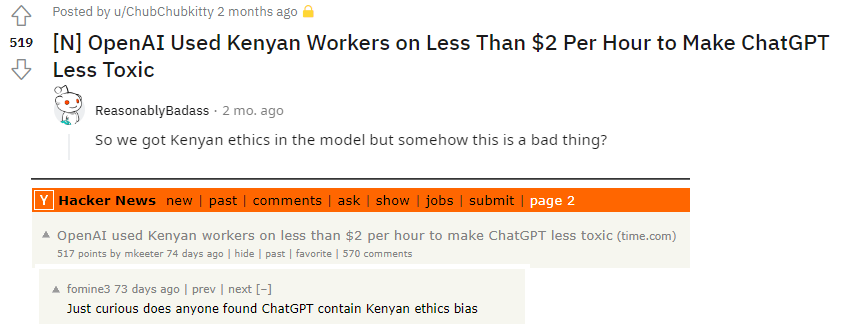
Fig 11: ‘Kenyan ethics’ baked in?
The devil is in the details: Imagining a typology of implementation paradigms
Before we dive deep into the details of specific implementation strategies, we’d like to set the stage by presenting a curated list of the main motivating factors at stake that will help contextualize the schema of solutions proposed.
- There’s an imminent risk of a dangerous schism between AI-augmented education sector in the west and the non-AI-augmented one in developing nations such as India that will have serious consequences to the already lopsided balance of power between the global north and the global south.
- Programming and hence, software engineering, is on the cusp of disruption. In many ways, the so termed software revolution of the 90s and 2000s gave India and Indian engineering talent a preeminent place on the global stage. Now, with software engineering standing on the cusp of disruption, it is imperative that we revamp our curricula strategically infusing LLMs via the schemes advocated below.
- As stated above, large tracts of the BPO sector stands on the cusp of disruption as well. Menial labeling tasks are getting automated out to LLMs faster than one thinks.
- On the bright side, there’s a once in a generation opportunity to create the newest and largest talent-pool of LLM knowhow and grab thought leadership in this domain by moving fast.
- With the rise and rise of LLMs, uniquely human content creation will emerge as a premium entity. Allowing our students to intimately grapple with LLMs will provide them with the front row seat towards understanding the qualia of creativity, thus potentially turning India into a bastion of creative content that will in turn provide us with tremendous leverage as a premium source of raw data to be fed into the next wave of LLMs.
- We can harness the emergence of the LLM-threat to finally address the rote-learning tropes oft-associated with the Indian educational sector. The rising evidence of how ChatGPT-like systems ace entrance examinations, should hopefully provide us with the needed impetus towards overhauling our exam-oriented system and turning it into one where the grading is decided on the measurable contributions produced by the students in lieu of masterfully memorizing the study materials.
- Subsidization: By establishing a virtuous loop between the LLM ecosystem and universities, the revenue generated by the students’ throughputs can be harnessed towards subsidizing their education.
With these thoughts firmly in tow, we now shift our focus towards two flavors of intervention proposed: Passive and Active. The terms active and passive have been developed in a student-centric framework focusing on the primary texture of their engagement with the technology. By passive, we mean those interventions where study-aid tools and curricula are developed for the students and by active, we mean those interventions generated by the students.
a) Passive interventions:
One of the biggest shortcomings of India’s educational sector, especially at the K-12 levels has been the stark difference in instruction quality between the predominantly urban top-tier institutions and their rural counterparts. We’d insist that we are at an exciting juncture where with the right utilization of LLMs, we can flatten the playing field for tens of million of kids, that will have incredible downstream consequences for the economy at large. The specific interventions we have envisioned to achieve this are:
1) Textbook2Chatbot, Short-form videos and teaching-aids: Flattening the playing-field and acad-tik-toks:
The concept of office hours is almost non-existent in the Indian setup. In our own personal experience, we had to dig out answers from the deep trenches of youtube or class-notes posted by western university professors to attain a certain level of clarity and mastery on the syllabi we were grappling with. Much akin to us, students often have no support structure to aid them in their academic journeys once they leave the school premises which is why there exists such a high level of private-tutoring enrollment rates even in on-entrance-examination scenarios. Now with the BYOD (Bring your own data)-Generative-AI revolution unfolding, we can turn textbooks into chatbots that the students anywhere can access, anytime and chat with anytime on their smartphones. We can also orchestrate this in such a way that the chatbot runs natively on the phone thereby further alleviating the concerns of asymmetrical implementation across areas with higher or lower levels of internet penetration. The other novel innovation we can unleash is the form of AI-generated short video content. Given that we are dealing with educating the TikTok/youtube-shorts generation with shortening attention spans, we can also condense and summarize the study materials into (sub)-minute-span video chunks to build academic-social-networks that can then leverage the network virality effect to popularize knowledge-flow across the student body. As far as harnessing Generative-AI in classrooms is concerned, universities such as U-Penn and University of Rochester have already stolen a march in the regard. Of particular note, is the paper: Using AI to Implement Effective Teaching Strategies in Classrooms: Five Strategies, Including Prompts by Dr. Ethan Mollick and Dr. Lilach Mollick at the Wharton School of Business (University of Pennsylvania), whose five-pronged strategy is summarized as below:
- Strategy 1: Using AI to Produce Many Varied Examples
- Strategy 2: Using AI to Provide Multiple Explanations
- Strategy 3: Using AI to Develop Low-Stakes Tests
- Strategy 4: Using AI to Assess Student Learning
- Strategy 5: Using AI to Distribute Practice of Important Ideas
As exciting as these possibilities sound, we also need to ensure that LLMs are not integrated over-zealously en-masse across all the departments keeping in mind the recent Vanderbilt fiasco where officials at Vanderbilt University has to apologize to the student body for callously using ChatGPT to craft a consoling email addressing the mass shooting at Michigan State University.
2) Curricula development:
**The emergence of LLMs has had a transformative effect on on the very institution of computer programming and has birthed a whole never flavor of technology perched on new ideas. The simultaneous rise of low/no-code tools such as bubble.io has made it possible for anyone with an idea and some minimal technical aptitude to create their own app! This has led to the birth of an entirely newly field that encapsulates a set of practices aimed at deploying and maintaining LLMs in production reliably and efficiently termed LLMOps (as an offshoot of MLOps). Similarly, we have also seen the emergence of an entirely new artform that deals with designing crafty prompt-inputs that deviate from plain vanilla human language prompts with the goal of getting LLMs to generate desired outputs (See cheat sheet below). This is called [Prompt engineering](https://www.cbsnews.com/news/ai-artificial-intelligence-chatgpt-jobs-prompt-engineer/).**
](/alignchronicles/assets/images/posts/whey_Untitled%201.png)
ChatGPT prompt cheat-sheet sourced from: https://hasantoxr.gumroad.com/l/cc
We have already witnessed the emergence of boot-camp styled coursework teaching the best practices associated with these newly emergent fields. For example, the Full stack deep learning team has already begun conducting LLM-Bootcamps (See https://fullstackdeeplearning.com/llm-bootcamp/) that cost $950 and tutors on Udemy have begun selling vast array of Prompt-engineering courses for $19.99 (Also see the LearnPromptEngineering resource page here: https://learnprompting.org/docs/category/-applied-prompting ). It is keeping in mind these rapid developments that we present a typology of curricular incorporating of these skill sets based on their temporal span:
- 1 day/weekend: Bootcamp and certification course hyper-focused on specific topics such as LLMOps , Prompt Engineering and Jailbreak landscapes
- 1 week: App and website building with just LLMs and no-code tools for creative entrepreneurs with non-CS backgrounds
- 1 semester: Elective subjects offered as part of CS, ECE and allied undergraduate and graduate courses covering topics such as competing LLM architectures, RLHF etc. A more intensive version of this can also be turned into a PG Diploma / Certification course.
-
1-2 year: MA / MS in LLMs.
As motivated in the section on LLMOps, the exponential growth of advances in this field along with its idiosyncratic instrumentation paradigm, has necessitated that we consider the possibility of offering a 1-1.5 year MS course specializing in LLMs. In this regard, we present a blueprint on what the course-contents could look like:
- Technical capacity building module: This module prepares the students to confidently handle the mathematical rigor and the software engineering intricacies associated with training, finetuning and deploying LLMs.
- Deep learning building blocks: NLP fundamentals, Tokenization, Transformer architecture
- Advances in distributed computing paradigms: GPU architecture, Specialized frameworks to train LLMs, Inference orchestration and model serving
- Advances in foundation models (Along the lines of CS324 developed at Stanford)
- Reinforcement learning, alignment and RLHF
- MLOps and LLM-ops
- Prompt engineering
- Iconoclasm building module
- Critical study of datasets used to train LLMs
- Survey of biases baked into LLMs
- Landscape of hallucinations exhibited by LLMs
- History of tech, ELIZA effect and the Clever Hans phenomena
- Creativity module:
- History of generative art
- Philosophical underpinnings and qualia of human creativity
-
Economics of LLMs
a. Cost of training these models
b. Carbon footprint of these models
c. Downstream repercussions on the labor sector
- Live Project work / thesis / term-paper
- Technical capacity building module: This module prepares the students to confidently handle the mathematical rigor and the software engineering intricacies associated with training, finetuning and deploying LLMs.
c) Emphasizing the whyness of the non-technical facets of the course:
- On nourishing LLM-iconoclasm amongst students: An LLM is quintessentially a weighted directed graph adroit at conditional next-token prediction. The fact that these weights are fine-tuned on internet sized corpuses has resulted in a slew of emergent properties, the most dangerous of which is human-like fluency in sentence formation. This uncanny human-like fluency attainment, in turn lends some verisimilitude to human-like-intelligence, an apparition that needs to be addressed on a war footing in the academic syllabi. Given that the training dataset is typically opaque, we need to take results such as the model passing some marquee exam with a grain, or rather, a pint of salt. These ‘breakthroughs’ can very well be explained away as training-set memorization, which is not a massive breakthrough by any stretch of imagination. Associating anthropocentric terms such as sentience, intelligence, morality and emotionality makes no sense in the context of LLMs and these associations have serious downstream implications for the society at large. Hence, students need to be given a grand tour of the models’ fallibilities, perhaps even emphasizing on the more frivolous ones so that it remains anchored in their minds that they are ultimately grappling with gargantuan token-vomit-machines (TVMs) that are just another kind of a machine learning model and nothing else. This flavor of iconoclasm we argue will turn the students into better technologists, especially when combined with the technical nous garnered from the other modules.
-
On the human creativity module:
We believe that providing students with a front row seat to the state-of-the-art AI-creativity advancements whilst also explaining to them the quintessential qualia of human creativity will not just make them skillful at using these Generative-AI-aided tools but will also allow them to clearly understand what makes human generated artform tick. This is crucial as this can help groom a strong bastion of human creativity which will be crucial going forward in the future where mass-generated AI-creativity has flooded the zeitgeist. It is very plausible that in the coming years, fresh human generated data will be hard to come by and future versions of GPT-x will be incestuously trained on data that its previous variant generated.
b) Active interventions
In this section, we present interventions where the student body actively participates in shaping, molding and contouring the LLMs to ensure that they are rendered more robust, safer and ultimately, useful for both, the society at large as well as for the incoming student-cohort. With this mind, we present an HF lab framework that can be laid out in 6 phases.
1) The 6 phase framework
- A multi-year MoU with an LLM institution: Right now, the LLM-land is littered with several competing startups all knowing very well that the secret sauce to break away from the rest of the pack is one whose recipe is out in the open: Human feedback! In lieu of going to another data-collection startup with dodgy labor-rights record, we propose that we seek out formal partnerships with students as providers of human feedback. This will ensure that not only the generated data will be of far higher quality and more nuanced, but also that the students will be well compensated for their effort, either as academic tuition rebates or as salaries. In Phase-1, we can pick that LLM that offers the best terms of agreement using a cost function that can be a weighted average of the following 5 factors: a) Revenue per student b) Infrastructural investments c) Post-graduation employment opportunities d) Faculty-training and upskilling e) Technology-sharing
As is ostensibly clear, scale clearly does matter and we argue that the signatory of such MoUs ought to be academic groups such as Jain Group of Institutions (with 85 educational institutions with 51,600 students) or MAHE (with ~ 23700 students) and not standalone engineering colleges.
- Infrastructure deployment
In this phase, we build out the infrastructure needed to orchestrate the human feedback sessions that has the following dimensions: Physical, Curricular and Software .
- Physical: This can be a separate on-campus human feedback lab or a rented out space such as the Computer science labs or the library. We would also strongly insist that there be a physical ethics and mental wellbeing institute on-campus staffed with counselors who can help the students navigate through the emotional and philosophical questions that may arise through the process. Another facet of physical infrastructure would be the hardware that constitutes the terminals on which the students will be running and a secure high-bandwidth broadband connection to connect the lab to the LLM servers
- Curricular: The students being initiated into the HF centers ought to be educated about the whyness of the task they are being exposed to and what the expectations are, which leads us to the next fact: Software infrastructure
- Software: The software infrastructure would cover components such as a culturally grounded graphical user interfaces with language translation technology baked in that will allow the students to seamlessly critique, rank and flag the outputs generated by the LLMs
- Stress-testing and red-teaming phase with experts
](/alignchronicles/assets/images/posts/whey_Untitled%202.png)
Fig 12: Source: https://arxiv.org/pdf/2210.07700.pdf
Before exposing the students to the LLMs, we ought to make sure that there is a phase of red-teaming by on-campus experts that will stress-test the LLM-feedback-tech to ensure that the students are not exposed to any harm. The template provided in a recent work [Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey](https://arxiv.org/pdf/2210.07700.pdf) (as seen in Fig above) covers the landscape of harms that can be used to construct a laundry list of anticpiated harms and efforts undertaken to quell them. We argue that it is imperative that the LLM company with whom the MoU has been signed be actively involved in this crucial phase of deployment.
- Introduction, limitation-awareness and orientation boot-camp: Before starting the feedback labs, the selected group of students need to be enrolled in a bootcamp-styled academic training where they are exposed to the thrill and challenges of the task ahead with enhanced focus on safety protocols, potential harm and nuances about the nature of the technology.
- Pilot Project / 1 semester with PG: Given that we are in unchartered territory, we strongly recommend that before scaling in cavalier manner, we test out the efficacy in one or two pilot projects spanning an entire academic semester with pre-established metrics and ensure that the proposed framework works. During this pilot study, we recommend that counselors be present in the lab alongside the students at all times to ensure that the first signs of any event that can potentially cause trauma to any given student be caught and nipped in the bud.
- Scaling across sister institutions Once we ensure that the metrics being tracked during the pilot study are indeed met, we can scale it in a multi-phase manner across the sister institutions of the academic group. We implore that the administrators repeat the pilot study if strongly negative trends or traits emerge during the first pilot-study after sufficiently incorporating the rectifications applicable as per the malaise encountered.